Next: Snapshot Up: lfs Previous: On-disc structures Contents
This chapter describes the concepts behind implementation of LFS kernel module. Please keep in mind that comments in the source code are an integral and indivisible part of the documentation. This document covers the implementation from a global perspective only, it is the comments that deal with individual implementation aspects and technicalities and that really describe what a particular function or a piece of code does.
This section briefly outlines the overall organization of in-memory structures specific to LFS. For information on general kernel structures, refer to the kernel source and kernel related literature such as [5]. Most of the in-memory structures are defined in src/types.h that is included from all c files. Nevertheless, there are other more specialized header files in the directory as well. All of them are described in table 5.1. Moreover, several c files define structures that are private to them. These will be dealt with in later sections where appropriate.
From now on, the on-disk structures are also referred to as raw structures. For example, whereas by an inode we usually mean the in-memory representation of an entity such as a file or a directory, the raw inode is used exclusively for a struct lfs_inode on the disk or its image in RAM.
As customary in the world of Linux file system programming, every kernel VFS structure has its file system specific info structure and there are LFS info structures that do not have an obvious kernel counterpart. Thus, every struct inode of LFS is actually a part of a struct lfs_inode_info which is accessible using inline function LFS_INODE(). This info contains, among other things, an image of the raw inode on the disk.
Similarly, there is an info for the superblock as well. It is called lfs_sb_info and is a parameter to most of the functions in the LFS kernel module. It can be obtained from the kernel struct superblock by feeding it to LFS_SBI(). Most other LFS memory structures can be obtained from it, in one way or another. In general, the superblock info has three types of fields:
Most other block device based Linux file systems use the device mapping to read, cache and store metadata including inodes and indirect blocks. When cache shrinks, this metadata is written to where they were read from by the device inode address space operations. Naturally this cannot be done in a file system that is log structured and therefore we have designed other means of keeping both entities in memory and writing them back to the disk.
Raw inodes are stored inside each instance of the corresponding struct lfs_inode_info. Allocation and deallocation of inodes is done in the same way other file systems that use inode infos do it. The system asks us to allocate an inode by a call to the alloc_inode superblock operation. In response, we allocate whole inode info from a slab but return only the pointer to the VFS struct inode. Deallocation is done similarly and automatically by by standard means of shrinking the dentry cache and reference counting.
As stated above, we also need a special mechanism to cache and write indirect blocks. We therefore store them in pages of a special address space or mapping which we refer to as the indirect mapping. It is stored in each struct lfs_inode_info in field idir_aspace. An index of a page stored in this mapping is the index of the first block stored in it (See section 4.3, particularly figure 4.1). This mapping has address space operations similar to those of ordinary data mappings. The indirect blocks are thus read and written in almost the same way as data blocks.
LFS fully exploits the inode and page caches. Unlike traditional file systems it does not map data to specific locations on the disk at the time the user space creates a given entity but much later when the data are to be written back to the disk. Nevertheless, when LFS accepts any data from the user space, it is then commited to writing them to disk because once we have informed the user program data were accepted, there is no way to revoke that decision. That is why the file system can refuse to write a given entity only when servicing the syscall or mmap.
In particular, the file system must check there is a free spot for a new entity such as an inode or a file block whenever a user creates one. This mechanism is called free space accounting. The idea is simple. We track the amount of free space in the superblock info and decrease it with every new accepted file block or inode. Because log structured file systems perform poorly when their disk utilization exceeds 80% (see [1] and [4]) and because a certain proportion of the disk must be used to store metadata, we do not allow the user to use more than exactly 80% of the underlying device and react with ENOSPC to any attempt to do so.
It is also possible that even though there is enough of free space for a write operation to succeed, the system is in an imminent shortage of free segments. In that particular situation, the garbage collector must be informed there is an emergency5.1 and all other processes must wait until it makes more segments available.
In order to do this we keep record of the total dirty pages and inodes in the system. When servicing a syscall that marks an inode or a page dirty we check whether we have enough free space in segments that are currently empty5.2 to write the entity in question without the need to call the garbage collector while keeping at least ten free segments at collector's disposal. If this test fails the garbage collector is sent an emergency message and the process is blocked until more segments become available. In the end we secure the newly dirty object a spot in the currently free segments, this accounting is therefore called preallocation.
Free space has already been allocated for a block if the pointer at it5.3 is non-zero (i.e. the block is not a hole). Because this pointer can contain a meaningful value only after the object leaves cache and is written to disk, a special value LFS_INODE_NEW is stored into it after it is accounted for and before it is actually written to disk. Blocks are freed by truncate which returns a block to the current free space whenever it discovers it has removed a block with a non-zero pointer. Every existing inode has always been accounted for, otherwise it wouldn't be created.
There is only one variable holding the free space per a mounted file system and it is free in free_space in the superblock info. It contains the number of inodes that the user is still allowed to store on the disk. Whenever free space for a block should be allocated, the number of inodes that entirely cover a block is subtracted from this value.
On the other hand, there are separate counters of preallocated blocks and inodes. One can tell whether an inode has been preallocated by examining its flags for the LFS_II_PREALLOCATED_BIT. A block is preallocated if and only if the highest order bit (LFS_INODE_PREALLOC_FLAG) of its pointer is set. That means only the lower 63 bits of the pointer actually contain the physical address of the block on the device and the pointer must be masked with LFS_INODE_ADDR_MASK whenever used. The function lfs_is_prealloc() returns whether a given pointer has the preallocation bit set or not.
Storing these state information in pointers and not for example in the corresponding buffer head flags is not accidental. Truncate must correctly update both free space accounting and preallocation but does not have the direct blocks or their buffer heads at its disposal because both have already been destroyed. On the other hand, inodes and indirect blocks still must exist and information stored therein is still accessible.
Moreover, it is essential that if a block is free space accounted for, all its superior indirect blocks are also. Similarly, a block that is preallocated has all its superior blocks preallocate too. Last but not least, the ifile blocks are never preallocated, there must always be enough space in free segments to store all dirty blocks, inodes and the whole ifile, no matter how many dirty blocks there are in the inode. Otherwise, emergency takes place. This decision ensures the segment building code which must never wait for the garbage collector can modify the ifile in any way it decides to.
We have already stressed that the file system must check whether there is enough free space when servicing a system call that creates the given new entity so that the user process can be informed should this test fail. Similarly, preallocation test must also be performed when servicing a system calls that marks a given object dirty because at that time it is safe to put the current process to sleep. In this way we avoid blocking processes that free memory by flushing the page cache which is essential because garbage collecting can be memory demanding and so this would lead to deadlocks and out-of-memory problems.
Data blocks can be created and marked dirty by the write syscall or any of its variants and through mmap5.4.In the former case, the implementation of the syscall invokes our prepare_write() address space operation. In the latter case, whenever a process is about to mark a page dirty through mmap, the kernel calls our page_mkwrite vm operation5.5 which also internally calls the same prepare_write().
This address space operation is then responsible for marking the given blocks dirty as well as all indirect blocks on the way to the inode and the inode itself. During this process, each newly created block is given a free space from the current free space variable and each non-preallocated block is preallocated. However, preallocation is split in two steps because a process waiting for the garbage collector must not have any pages locked or hold certain semaphores. Therefore, enough preallocation blocks are acquired right in the beginning. If there are not enough free segments, the process releases the page held, blocks until there are enough segments and then always immediately returns AOP_TRUNCATED_PAGE. The caller is then responsible for reacquiring the necessary page and calling the operation again. Once the necessary number of blocks is acquired, they are distributed among the current block and its superior blocks, if they haven't been already preallocated. At this point, the highest order bits in their pointers are set, as described above. Finally, all unused acquired preallocation blocks are returned to the global variable. Directory operations and truncate acquire preallocation blocks themselves because they need to do it before locking certain semaphores.
Free space is acquired for inodes when they are created in the lfs_ifile_new_ino(). Inodes are preallocated whenever they are marked dirty in our handler of dirty_inode() super operation. However, this handler must not sleep and so the process must be suspended later on when processing either a prepare_write() or set_attr() operations.
Free space is returned when truncate is about to free a block that was not a hole or an inode is deleted. Preallocation is returned whenever a dirty block or an inode is sent to the disk. The code that writes back dirty indirect blocks refuses to write those containing preallocated pointers. Similarly, pointers in inodes are masked before being written. Therefore, there is a per-inode read write semaphore to mutually exclude inode syncs and prepare_write() because otherwise some indirect blocks might not have been synced.
LFS leaves the generic kernel functions to deliver data from the page cache to the user space, whether in the form of standard read system call, any of its variants or mmap. When reading data, LFS only fills in the cache.
First of all, however, the inode must be read, usually as an indirect response to a call to iget(). This means its address is retrieved from the ifile, the raw inode is read from that address (both operations are performed in lfs_read_inode_internal()) and finally the inode info together with kernel VFS inode are both initialized with the read data (in lfs_read_inode()). There is an exception to this rule which takes place when the inode in question is currently being written and which is described in section 5.6.
Pages from the data mappings are read by generic functions mpage_readpage() and mpage_readpages() and both use lfs_get_block() to map a given buffer to a specific spot on the disk. Pages of the indirect mapping are read by our function lfs_indirect_readpage() which is a modification of a generic kernel function block_read_full_page() that does not check whether reads exceed the file size. This function internally calls lfs_get_block_indirect() to map buffers to locations to disk. Both mapping functions in the end call read_block() which either looks up the required position from a pointer in an inode or uses the same mechanism to read a superior indirect page and locates the corresponding pointer there.
This section describes how dirty data in various caches get written to disk. Please note that this chapter does not cover the sync operation which requires specific consistency measures. It will be dealt with thoroughly in the section 5.4.
All data and metadata except superblocks are written into a log consisting of segments. At any given moment the currently written data are being stored into a particular segment and a particular partial segment. Moreover, data has not been written safely until at least a partial segment is finished. Therefore, the code that writes data to the disk is usually called the segment building code. It is almost entirely present in src/log.c. This part of the file system, complex as it is, naturally has its own info structure. It is called struct lfs_log_info and you can find it in src/types.h. This structure is actually a part of the superblock info (see section 5.1.1) called log. We will often refer to various fields in the log info throughout this section.
The Linux kernel, LFS garbage collector and LFS journaling subsystem can ask the segment building to perform these operations:
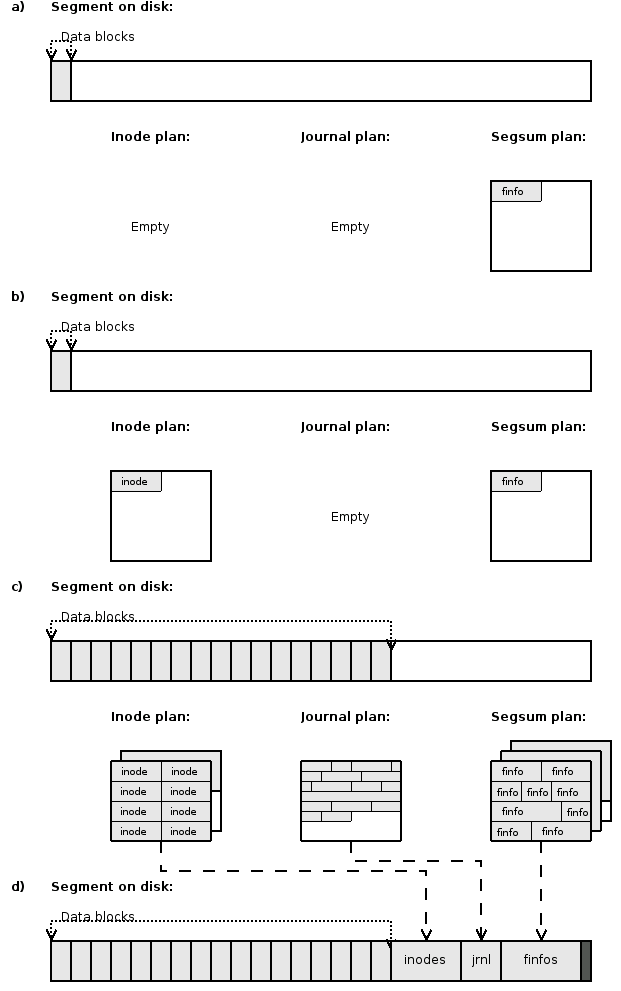 |
Now let us have a look at various stages of building a partial segment (see also figure 5.1):
Every time we write segment we must know what the next one will be (see section 4.7 and figure 4.6). Therefore, we always need to request a segment in advance a call to usage_get_seg() so that the segment management subsystem finds a new segment for us. All that has been described in this point so far is done by function find_segment().
Finally, majority of log info structures are initialized in init_ordinary_segment().
However, there is more to be done. At the same time, finfo structures are prepared in memory so that when the segment is about to be finished, they can be written to disk. Similarly, journal pages that contain jlines related to the processed inode (the inode to which the written pages belong) are retrieved from the journaling subsystem and queued for writing which will take place when the segment is about to be finished.
This means that there can be a lot of data waiting in the memory to be written just before the current partial segment is closed. It is essential to guarantee there will be enough space in the current segment for all of it. This is accomplished by a remaining blocks counter in the log info called remblock which is decremented each time a block of data is written to the disk or sizes of planned finfos, journals or inodes (see below) grow beyond another block. When this number reaches zero, the current segment must be finished.
Writing pages and queuing inodes of course can and often does interleave.
Finishing segment basically means flushing inodes, journals and finfos to disk, calculating CRCs and creating a segment summary. Finishing partial segments also involves creation of a phantom partial segment (i.e. its summary). The whole procedure is described in detail in the section 5.3.7.
The fact that we do not queue dirty blocks is very desirable as it prevents various out of memory (OOM) problems and lockups. This is exactly the reason why have chosen the structure of LFS segments with a segment summary at the end rather that at the beginning (see section 4.8).
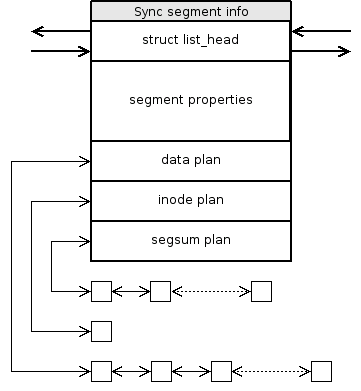
Storing inodes, journals and finfos as described above clearly needs some common infrastructure. We say that this data are planned to be written and the queues that store them are called plans. Normal segment building code uses an inode plan, a journal plan and a segsum plan, all of which are directly accessible from the log info. The segsum plan actually contains mainly finfos and has its name because in the early stages of the LFS project, finfos were considered a part of the segment summary. Nevertheless, the segsum plan also often contains the segment summary (see section 5.3.7) even though it may not necessarily be so. Plans are also extensively used when syncing the ifile but that is outside of the scope of this section and is covered properly in the section 5.4.
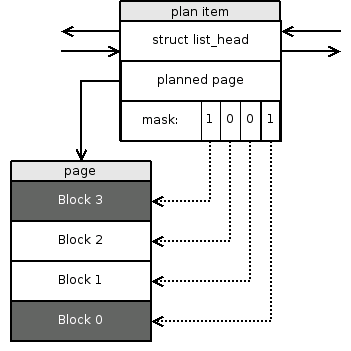 |
A plan is merely a list of struct lfs_plan_item instances. Each structure contains a pointer to a page with the planned data and a bit mask that tells which blocks in the page are supposed to be written and which are not5.7. The lowest-order bit of the mask corresponds to the first block within the page, the second lowest to the second block and so on. When a bit in the mask is set, the corresponding block is about to be written and the other way round. Figure 5.2 gives an example. Plan items are kept in a standard kernel linked list and together they form a plan chain.
All planned pages must be allocated by alloc_pages() so that once they are written they can be freed by __free_pages(). The plan items themselves are obtained from plan_slab slab. All plans considered in this section are empty when a new partial segment is initialized. New items are added to them and other operations are performed on them by functions listed in table 5.2. The way plan chains are written to the device will be described in section 5.3.7, their deallocation (under normal conditions) in section 5.3.8.
|
It is self-evident that most of the write operations must be serialized because there is only one segment being built and pages appended to its end at any moment. In order to simplify matters further, we have decided to serialize all of them by a mutex. The mutex is located in log info and is called log_mutex. All operations discussed above either themselves lock it or require it is already acquired.
The segment building module must also be synchronized with other events in the kernel, most notably truncate. That is why all inode infos contain a read-write semaphore called truncate_rwsem which is locked for reading whenever working with a particular inode or pages belonging to either of its mappings. Truncate itself locks it for writing because it locks the pages in the opposite order than all other operations. A great deal of synchronization is also performed through Linux page locks, most of which is not specific to LFS. On the other hand, the pointers in inodes and indirect blocks are protected by page locks of the block they correspond to.
Order of locking is the key instrument to avoid deadlocks. In this case, the log_mutex must be acquired first, the truncate_rwsem second and only afterwards a page can be locked. This requirement forces a small hack in lfs_writepage() (see below).
Linux kernel can ask a file system to write out a single page or to try to find a specified number of dirty pages in a mapping and flush them. The first request is communicated to LFS by calling the writepage() address space operation and is handled by the LFS segment building code for both data and indirect mappings. Both handlers do nothing but call lfs_writepage() with a correct value in its indirect parameter. On the other hand, writing out several dirty pages from a given mapping is performed by the writepages() address space operation which is also handled by LFS for both kind of mappings. Like in the previous case, they call a common routine lfs_writepages(). See a subset of the call graph of the page writeout handlers on the figure 5.3.
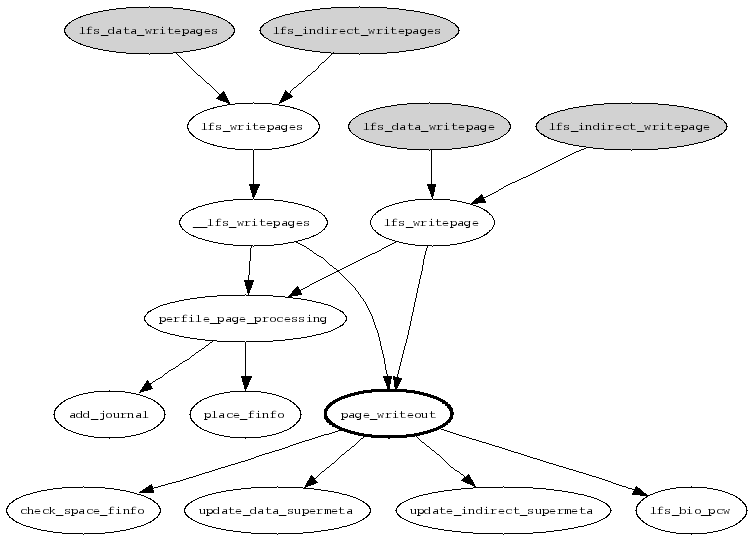 |
lfs_writepage() gets the page that needs to be written as a parameter. The page is obtained locked which violates the required lock ordering (see section 5.3.4 above). The page is therefore released, log_mutex and truncate semaphore are acquired and then the page is locked again. The code of course must check it has not been truncated and is still suitable for writing5.8.
Afterwards the page cache writeout control structure (see below) is initialized and perfile_page_processing() called. This function is invoked each time a different inode is being written. It uses add_journal() to plan all jlines relevant to this inode and place_finfo() to create a new finfo header in the segsum plan. The latter function is a bit complex because the new finfo header can span across block and page boundaries and different actions must be taken in each case.
The most important function called at this place is page_writeout() which inspects the page and initiates I/O. We will deal with this function separately below.
Finally, lfs_writepage calls lfs_submit_pcw() to submit any pending BIO request, unlocks the locks held and calls write_gc_stuff() to process potential requests from the garbage collector.
The only task of lfs_writepages() is to interleave the writes requested by the Linux kernel with those required by the garbage collector. The garbage collector requests are honored first and with no upper limit on the total number of pages written in one go so that there are segments ready when they are needed for new data. The garbage is written by write_gc_stuff() like in the previous case.
Writing dirty pages of the given mapping is the task of __lfs_writepages(). The function is similar to Linux kernel generic mpage_writepages() function. It acquires the log mutex first so that if it creates a finfo header it will remain the current header throughout the rest of its execution. Next, the function obtains a private array of page pointers with dirty pages of the given mapping and processes them one by one. Each page is locked and checked whether it should still be written (i.e. it has not been truncated and is still dirty).
perfile_page_processing() is called once if there has been a dirty page in the given mapping. The function performs the same tasks as in the case of writepage(). On the other hand, page_writeout() which is described below is called on every valid dirty page.
__lfs_writepages() can be limited in the number of pages to flush to the disk so that the garbage collector items are guaranteed to be processed once in a while. When this maximum number has been reached or all dirty pages have been written, the function submits any pending BIO, unlocks log mutex and returns. In that case it returns a special value so that lfs_writepages() calls it again after it has honored all pending garbage collector requests.
__lfs_writepages(), lfs_writepage() and page_writeout() and a few other minor functions need to share a great deal of parameters. For the reasons of clarity of the code, these have been placed into a structure called struct pcw_control (page cache writeout control structure). Its contents includes a reference to the current page, whether the page is indirect, the inode, the obtained Linux kernel writeback control structure and other status information. Most importantly, however, there is also a reference to the current BIO (see [5], chapter 13) that is shared among different invocations of page_writeout() within a single execution of __lfs_writepages(). The structure also contains information about the currently processed block and the current dirty area of the page which can be added to the BIO by lfs_bio_pcw(). If the current BIO becomes full, it is submitted and a new one allocated. Finally, the last unsubmitted I/O vector is sent to the block layer by lfs_submit_pcw().
The most important function in this context that has not yet been discussed in detail is page_writeout(). The function begins with initializing a few structures of the page cache writeout control structure it has obtained from the caller. Next, if the page straddles the end of file, the part behind the end is cleared with zeros.
Most importantly, the function traverses dirty page buffers and performs the following actions:
In the end, the page is marked as under writeback and unlocked.
Please note that this is just a brief outline, refer to the source code for details.
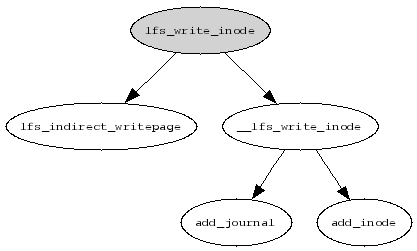 |
Writing inodes is much simpler but it is done in two phases. First, an inode is planned. Later on, when the current segment is being finished, its metadata are updated and the raw inode is written to disk. The call graph of the first phase can be found in figure 5.4.
Linux kernel does not know about LFS indirect mappings. It can therefore issue destruction of an inode that has dirty pages in its indirect mapping. In order to avoid this, the dirty mapping is synced by lfs_write_inode() each time an inode is about to be planned to be written.
__lfs_write_inode() takes care of locking (it locks both the log_mutex and inode's truncate rwsem) and journal planning. Most importantly, it calls add_inode() to add the inode to the current inode plan. Both actions can cause the current segment to be finished and a new one started.
add_inode() attempts to lookup the inode in the ihash (see section 5.6) and if it succeeds, it copies the new raw inode over the old one. Otherwise it copies the raw inode into a planned allocated page. The latter case can involve page and plan allocation, updating and checking the number of remaining blocks in this segment and even segment finishing.
The final placement of the planned inodes are not known until the segment is being finished. The inode table cannot be therefore updated and relevant segment writeouts (see section 5.8) issued until this moment. Therefore, before the inodes are actually sent to the device, update_inode_table() is called to process the inode plan. It traverses the plan chain and calls update_itable_entry() on every raw inode. This function updates the relevant inode table entries and issues the segment writeouts. Not surprisingly, the ifile inode is handled in a special way because its inode table entry is not used and writeouts are issued differently during sync (see section 5.4).
When a partial segment is being finished by __finish_segment(), it proceeds with the following steps:
The BIOs issued by LFS can be of the following types:
|
Another and perhaps more important division between BIOs is into those which write page cache pages and those that write pages allocated by alloc_pages(). The first group currently uses the bioend_pcache_simple() to clear the pages' writeback flag when the write is finished. Nevertheless, there is a handler ready for filesystems with multiple blocks per page called bioend_pcache_partial().
Allocated pages are deallocated by __bioend_free_all() after they are flushed to the disk. Pages carrying inodes are processed by bioend_remove_inodes() so that written inodes are removed from ihash before the deallocation happens. Moreover, these BIOs may be issued as barriers. Linux kernel BIO barrier is a special BIO flag described in [6] that prevents the block layer from reordering write requests across this particular one. LFS issues barriers when finishing segments for several reasons. The most obvious is waiting on I/O to finish before we exit from sync and fsync. However, we also issue barriers every time we finish a segment so that we know all data marked as written out in the segment usage table have actually been written out and this information is then propagated to segment management.
Because barriers are used for a variety of purposes in LFS we internally differentiate in between three types of barriers. BIOs issued as barriers carry along them a small structure called lfs_barrier_info that contain information internal to segment management, the barrier kind and so on. The three types of barriers are:
When a BIO finish handler detects an error, it sets the failure flag in log info and adds the number of the current segment into an array in the same structure. A few functions that have already been mentioned in this section call check_failure() to check the flag and if it is set to start a new physical segment and mark all segments in the array mentioned above as bad. The emergency flag is also set when a new segment cannot be initiated due to an I/O error.
When garbage collector identifies the live data and inodes in a segment that is about to be cleaned, it queues this information and then invokes write_gc_stuff() to write all queued entities to a new location. In order to guarantee a certain degree of priority to the garbage collected data, ordinary segment building functions also regularly call this function regularly.
Garbage collector does not store individual pages but mappings that are written by __lfs_writepages() described earlier in this section. On the other hand, inodes are returned individually and they are planned by a direct call to __lfs_write_inode(). Garbage collection of inodes therefore does not involve syncing the indirect mapping because it is not necessary.
Implementation of the sync syscall must ensure three things:
Cached data are flushed partly by the Linux kernel but unfortunately it does not guarantee all of it is synced before the sync super block operation is called. We therefore keep a list of dirty inodes and sync all of them in that operation ourselves. This list and all relevant functions can be found in file src/consistency.c and they should be fairly simple to understand. This queue never contains the ifile which is taken care of differently later on.
While flushing the cache, we must make sure either all or no parts of a directory operation (all inodes and the jlines) are sent to disk. This is achieved by a read-write semaphore that is tweaked a bit so that it does not starve the writer. Directory operations lock it for reading while the sync functions down it for writing. Finally, after the semaphore is acquired for writing and before dirty inodes are synced, the journaling subsystem is forced to start a new page so that a jline does not span across the sync. The old jlines are then flushed to disk when the relevant inodes or their parts are.
Whenever a block is written to a new position on the disk, the segment usage table is updated because the number of live blocks of the old segment is decremented (this is also referred to as a usage writeout). Moreover, whenever a segment is finished, the table must also be updated with the new numbers of blocks and inodes residing in the new segment. Both operations therefore mean that pages of the ifile are marked dirty. This means that trying to obtain a consistent image of the ifile by iteratively writing all dirty pages until all of them are clean would result into an infinite loop. The solution to this problem is to plan the writes rather than immediately flush them to the device. In this way, if a page is dirty but it has already been planned, it is not planned again.
The infrastructure to plan pages has been described in section 5.3.3. When syncing, it is also used to plan the ifile page cache pages and associated finfos. The only planned inode during this phase of a sync is the ifile inode and it is the last planned entity during the ifile sync. There are no journals processed during this last stage.
The ifile, however, can span across multiple (partial) segments. The structure lfs_sync_segment (see figure 5.5) represents such a partial segment. They are chained together by a linked list and represent a plan of segments (see figure 5.6). The whole chain is accessible from the log info's segments field, the current one can be found in cur_sseg in the same structure. Each structure, among other things, stores its own plan of page cache pages, inode plan and a segsum plan. If there is a phantom or separate segment summary, it is flagged in the relevant field and allocated in the given page. These structures are updated as pages and inodes are being planned. Once remblock reaches zero, the current segment is enqueued by finish_sync_segment() and a new one is created and initialized by init_sync_segment().
The strategy of producing the sync plan is the following. First, we sweep through both data and indirect mapping of the inode and plan all dirty pages we find. Identifying the dirty pages is done in function sync_ifile_mapping(), the pages are then locked by lock_add_ifile_page(). These two functions are in many ways similar to __lfs_writepages(). Buffers of these pages are then processed by add_ifile_page() which may resemble page_writeout() but differs in a few important aspects.
As we have already said, it does not issue I/O but plans the dirty buffers instead. One of the key features is that when any other block (of the ifile) is marked dirty due to metadata updates, it is enqueued as a request to write. The request is formed of a list of small page handlers called struct sync_req (see figure 5.7) which refer to a page and indicate from what mapping that page comes. Pages are added to this queue at two occasions: When pointers in indirect blocks are modified and when segment usage table entries are updated. In the latter case, the segment management code actually enqueues the relevant buffers by calling lfs_sync_enqueue_buffer(). After both mappings are traversed, the pages in the request queue are planned by lock_add_ifile_page() until the queue is empty.
To avoid planning or queuing pages that are already planned or queued, two LFS specific buffer_head flags have been introduced. The first one is called queued and is set when the page containing this buffer has been enqueued because this buffer has been marked dirty. The second one is known as planned and it is set when the buffer is included in the data plan of the current sync segment plan. Both flags are cleared just before their data plan is sent to disk and under certain error conditions. Understandably, a buffer is not queued if it has either of the flags set and it is not planned unless its planned flag is zero.
When the request queue has been emptied, the ifile inode is added to it and the current sync segment planning is finished.
The plan that has been built as described in the previous section is then flushed to disk by bio_ifile_sync(). This function processes the planned segments one after another in two steps. First, the buffer flags described in previous section are cleared in all queued buffers and then all planned entities are flushed to disk by bio_sync_segment(). This function issues BIOs in a way similar to __finish_segment() and also issues a sync barrier (see section 5.3.8) after flushing the last segment.
When all BIOs have been submitted, a new ordinary segment is initialized, the superblock is written so that its raw image on the disk contains the new ifile inode address, next block and segment counter. This is followed by waiting on the sync barrier BIO to complete. Finally, as locks are unlocked, the file system has been successfully synced and the segment management subsystem and the garbage collector are informed about it (see section 5.8.3).
Implementation of fsync in LFS is very simple. It consists of flushing cached data from both data and indirect mappings, planning the inode and finishing the current partial segment (which in turn writes the raw inode to disk). If a system failure occurs after this point, the roll forward utility will be able to recover the written data.
There are two potential problems with planning and late flushing of inodes as described in the section 5.3.6:
Ihash is a double pointer hash table consisting of 8192 lfs_ihash_entry structures (see figure 5.8). Each entry with a non-zero ino contains a pointer to a planned raw inode and a writeback flag indicating it is already being written by a BIO.
As already mentioned above, the ihash is a double pointer hash table. In order to locate an inode stored in it, its inode number is hashed by hash function hash_long() provided by kernel to calculate its chain number. The chain number is used as an index to the hash table and the first field of the obtained structure is examined because it contains the index at which the particular chain begins. Chain items are connected in a single direction linked list by the next index. All functions using and manipulating the ihash can be founds in src/ihash.c and should be easy to understand.
Manipulating and searching the ihash is always protected by a spinlock in the ihash info structure that is a part of the superblock info.
The ihash is used twice when an inode is planned. Before a new spot is allocated for a raw inode LFS tries to find it in the ihash. If it is found and is not undergoing writeback, the raw inode that is already planned is overwritten with new data. This ensures a single inode is never present multiple times in a partial segment which was happening quite often before ihash was implemented. If the inode is not already present in the ihash, it is inserted and if it is present but marked as under writeback, the pointer in the ihash entry is updated and the writeback flag cleared.
Conversely, when an inode is requested to be read, the ihash is tried first. If it is found in the ihash, the raw data referenced there are used regardless of the writeback flag. On the other hand when inodes are being deleted, they are removed from the ihash because the associated ihash item no longer contains valid information.
Just before all inodes are sent to disk, all entries in the ihash are marked as under writeback. When a BIO carrying inodes terminates, the finish handler identifies all inodes present in the pages that were written and deletes their entries from the ihash, unless their writeback is not set which happens when the inode was re-inserted into the hash after the I/O has been submitted.
From the Linux kernel's perspective, the file truncate operation is divided into two phases. First, the inode size is set to the new value, the data mapping is truncated to reflect the new size and the straddling part of the last page is cleared with zeroes. Afterwards, the file system is told to update its own private structures to reflect the new size by invoking the file system's truncate inode operation.
LFS must do three things. Obviously, pointers to blocks in the inode and indirect blocks must be invalidated, free space accounting and preallocation state must be updated and segment writeouts must be issued so that segments can be freed. All these tasks are performed by calling lfs_trunc_iblocks(). Dealing with direct addresses stored in the inode is easy. If such a pointer is ``behind'' the new file size and contains a non-zero value, it is cleared (by __inode_set_addr()), one block is added to the free space accounting and a block is subtracted from the corresponding segment usage table item by function __free_block(). This function also checks the preallocation flag of the discarded block and if it is set decrements the global counter of preallocated pages. Altogether, we say that such a block is dropped.
The real challenge here are the indirect blocks. Consider the example in figure 5.9. The highlighted address in indirect block points to the new last block of the given file. It is evident that the whole indirect block must be removed, entirely kept and roughly a half of entries must be cleared in block .
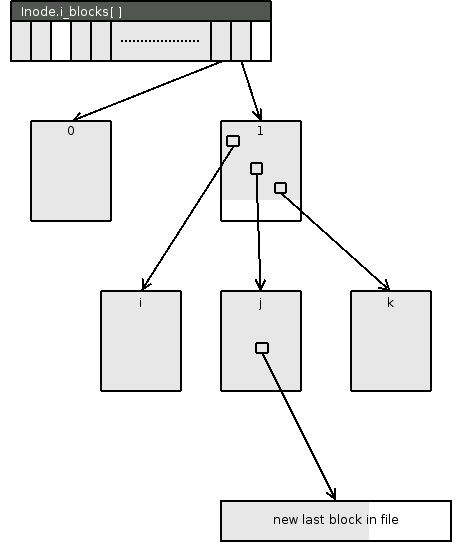 |
lfs_trunc_iblocks() starts by calling __dblock_to_path() to identify all indirect blocks through which the end of file ``passes''. Then at each level of indirection, the addresses with higher indices and their children are dropped fully while the one exactly at the particular index is dropped partially. However, even a partial drop may end up as a whole one when the file ends exactly at the border of the first of the block in question.
Speaking implementation-wise, we start with calling __drop_iblock_partialy() on the identified border block at the highest level (the block in the example on the figure 5.9). If we are not at leaf level, the same function is called on the border block one level below (block in the same example). In any case, all non-hole indices higher than the border index are dropped by __drop_iblock_whole(). If the block finds out it is completely empty, it signals this to the caller so that it can do the same decision and clear the relevant address. Full drops mean the whole subtree is traversed and any non-hole pointer is dropped unconditionally. Finally, the no longer necessary indirect pages are themselves truncated.
The whole operation described in this section is performed with truncate_rwsem of the relevant inode locked for writing so that any actions do not interfere with the segment building code or garbage collection (see section 5.3.4).
Segments are the basic unit of free space reclaim of all log structured file systems, a segment can be reused only once all live data have been either deleted or moved elsewhere. This basic rule requires the LFS to track the state of all segments and dictates an ability to find a new empty segment for future writebacks whenever necessary. The state of a segment consists of the number of inodes and blocks stored in it, various flags and its segment counter. The basic structure used to persistently store all this information for each segment is the segment usage table stored in the ifile (see section 4.5). A segment can fall into any one of the following categories:
|
When the segment building subsystem finishes with a full physical segment, it needs to obtain the next one to write to. Any empty segment will do but locating it in the segment usage table would be costly. The subsystem therefore maintains a bitmap free_seg_map in the ifile info5.9. This bitmap contains exactly one bit for each segment which is set if and only if the corresponding segment can be immediately overwritten. The segment building subsystem requests segments by calling usage_get_seg(). This function simply finds a set bit in the bitmap, clears it and returns the corresponding segment number. The function may block in the unlikely case there is no segment available. In that case, a number of BIOs must be under way and their completion will make some segments available and wake up the sleeping process.
A segment summary must be updated whenever an entity stored within it dies. Whenever the segment building subsystem moves an entity from a segment elsewhere, a truncate operation frees a block or an inode is deleted, usage_writeout_block() or usage_writeout_inode() is called. Both these functions internally call a common routine __usage_writeout() which updates the segment usage table and sends a message to the user space garbage collector so that it can also update its internal state (see section 5.10). Because this operation usually informs the segment management some data have been written out of the segment elsewhere, it is referred to as a segment writeout.
Reusing a segment immediately after the last segment writeout indicated all data in the segment are dead can lead to data loss. Consider the following situation. The segment building code has issued that last writeout and initiated a BIO writing the updated data to a different spot on the disk. If the system crashes before the current partial segment is completely finished, the data cannot be recovered from the new position because the roll forward utility cannot handle unfinished partial segments. If the old segment was meanwhile reused, the data in question could be lost.
This is the reason for distinguishing the possibly free segments from empty ones explained earlier in this section. When actual usage of a segment reaches zero, the segment is put into free_seg_list in ifile info together with a unique number free_counter. Whenever the segment building finishes a segment, it queries the current value of this counter by calling usage_get_free_counter() and stores it alongside the last BIO of this segment. The completion handler then passes this value back to segment management subsystem by invoking usage_disk_sync(). Because this function is therefore called in the interrupt context and a mutex must be acquired when manipulating the free segment queue, it only stores the passed counter. Later on, lfs_update_free_segment() is called at various places when it is safe to block on a mutex. This function processes free_seg_list and marks those segments that conform to all three following criteria as empty:
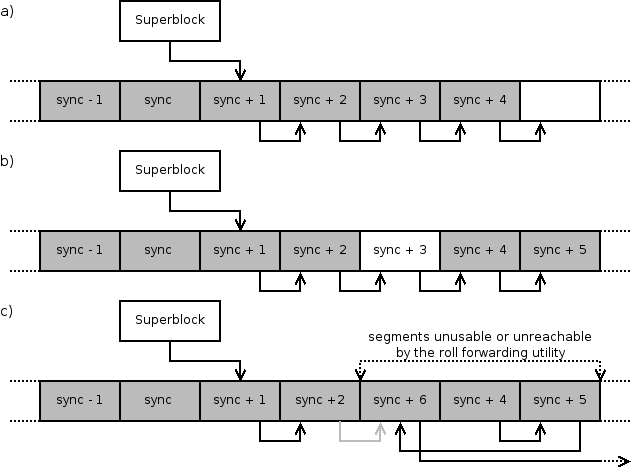 |
Points two and three above mean that only segments younger than the last snapshot segment and older than the first segment after last sync can be reclaimed. This time interval is called the window. Point one guarantees either the old or the new copy is on the disk at any time. On the other hand, if the machine crashes before the next sync, the roll forwarding utility is needed to recover moved data. Please note that garbage collector may decide to move virtually any data at any time so this does not apply only to the entities a user has deliberately modified.
When segments are marked as empty all processes that might be blocked waiting for them are awaken by calling wake_up() on the free_seg_cond queue.
Occasionally, segment writeouts are issued against the segment that is being written to at the same time. They are mostly results of truncation of data that have just been written to the disk but sometimes even the same block is written to the same partial segment multiple times. Because the amount of live data stored in the segment usage table is set after the whole partial segment is written, this could cause the usage of the segment to become negative, confusing both segment manager and garbage collector. In order to prevent this, writeouts from the currently written segment, the so called working area, are not immediately reflected in the segment usage table but held aside to be processed once at least a partial segment is finished.
Moreover, when the segment usage of the active segment drops to zero after finishing a partial segment, the segment must not be marked as potentially free. This can be done only when the whole physical segment is finished and the segment building code moves on to the next one.
In order to prevent situations like the one depicted on figure 5.10 we do not allow recycling and garbage collection of segments that are younger than the last sync. A periodic sync ensures that the number of affected segments is always relatively small. Periodic syncing is done by the lfs-sync thread that repeatedly tests how many new segments have been written by a log structured file system since the last sync. If the number has been bigger than a threshold value, a sync is issued. The threshold value is computed as maximum of ten percent of the currently free segments in the file system and 10. There is only one such thread in the system that services all currently mounted LFS instances.
We have already stated in section 5.8 that LFS reclaims free space with segment granularity and that only segments that contain no live data may be reused. In order to manage disk space effectively, data in underutilized segments must be moved to new full segments. The process of doing so is often referred to as garbage collection. Basically, it consists of identifying live data in the underutilized segments and write it as usual to a new segment.
Because the process of deciding which segments should be garbage collected is complex and in future we intend to support multiple such algorithms at the same time, it has been moved to the user space. This chapter considers the kernel module internals only, details of the user space program can be found in section 7.2. Once this program determines which segments are to be cleaned, it is again the kernel module's job to identify the live data and write them to the current end of the file system log. The kernel part and the user program communicate through the NETLINK protocol.
The NETLINK communication interface allows each message to be sent to either one particular process defined by its pid or a group of processes identified by a group id. User space garbage collector starts by sending a handshake message to the kernel which in turn registers to its array of active garbage collectors to which it unicasts the necessary messages. Unicast is necessary because delivery of each message must be guaranteed, a feature that is not provided by the multicast infrastructure.
The kernel module can send any of the following messages to the user space collectors (so called info messages):
Below is an overview of all message types that the user space program can send to the kernel module (so called requests):
We have already said that all messages must be reliably delivered to the user space. Reliable delivery, however, is always blocking. That is why messages are sent to the user space by a special thread called gc-thread. Every mounted file system has an outgoing message queue called work_queue5.10 associated with it. New messages are usually added to it using the function schedule_message().
LFS_GC_INFO_WORK and LFS_GC_INFO_PING messages may take a considerable amount of time to process because the garbage collector may issue collecting requests which are then honored in kernel but within its context. Even more importantly, processing those requests inevitably generates a fairly big amount of new info messages which can lead to an uncontrollable growth of the outgoing message queue. Furthermore, if the user space decided which segment should be cleaned before it processed all information about segment usage changes, it would be basing its actions on potentially outdated data. In order to avoid these two unpleasant situations, various info messages have different priorities and are inserted into the work_queue accordingly. Generally speaking, messages updating the internal state of the user space garbage collector take precedence over those that might result into more collection. All priorities are listed in table 5.5.
|
All requests from the user space are immediately processed by the NETLINK event handler gc_request() within the context of the cleaner. Registering a new garbage collector and processing the ping answers is fairly straightforward and therefore we will deal only with requests for a specific segment collection which are handled by gc_request_collect() which in turn calls the function gc_collector() to do most of the work.
This function proceeds in several steps. First, it checks the segment can actually be collected and is not empty. Secondly, it reads and checks the segment summary. Finally, it invokes collect_data() and collect_inodes() to collect blocks and inodes respectively. These functions determine the liveness of all blocks and inodes stored in the segment. Each live block is read, marked dirty and the associated mapping is placed into the garbage queue so that the segment building code can write it to a new location (see section 5.3.10). Each live inode has its LFS_II_COLLECTED_BIT flag set and is also added to the same queue. Note the inodes are not marked dirty because otherwise the Linux kernel might try to write it back to the disk itself which might occasionally lead to the inode being written twice. The purpose of the flag is also to prevent this from happening, it is cleared each time an inode is planned for writeback. Whenever an inode or a block is put into the queue, the reference of the inode is incremented so that it is never deallocated until the reference is decremented again by the segment building code after it has written the entity to a new location.
Finally, gc_request_collect() calls the function lfs_write_gc_stuff() (see section 5.3.10) so that the items stored in the garbage queue are immediately written.
The traditional layout of directories as a table of entries which grows when entries are added is deprecated. The drawback of the old approach is that the complexity of directory operations is linear. This results in a quadratic cost of an operation performed on all entries within a directory.
Modern filesystems adopted methods which allow to access an entry with a constant (or almost constant) cost. Most of the current file systems implementors decided to use B+Tree (JFS, NTFS, HPFS, XFS), B*Tree (HFS Plus) or some sort of hash tables (ZFS - extensible hash table).
Not surprisingly also the EXT3 developers had to deal with this trend and implemented an indexed directory structure called HTREE (as described in [7]) which is backward compatible with the traditional EXT2 layout, but offers the main features of an indexed directory. Moreover in case of a file system damage, there is a fall-back to the non-indexed operations.
For our LFS project we decided to uses a the HTREE with certain changes to its structure since we are not bound to the backward compatibility. HTREE is in fact a variation of a B+Tree, all data are in leaf blocks and all leafs are in the same depth. This chapter describes our indexed-directory implementation as well as discuss all major design decisions we took.
As mentioned before our intention is to implement a directory layout that has an almost constant cost of file operations. Usually a file system with indexed directory structure handles very small directories in a different (unindexed) way avoiding the index overhead until the number of directory entries exceeds some threshold. JFS stores up to 8 entries (excluding . and ..) in the inode without need of an additional data block whereas the EXT3 uses EXT2 layout for a single block directories.
In our design (inspired by the EXT3 HTREE [7]) we also begins with a single block directory without any indexing. There is a marker in the inode which tells whether the directory is indexed or not. If a new entry is being created, but there is no free space in the current data block, that block is split, data are equally copied to two new data blocks and an index block (index root) is created. The data blocks become leaves of the newly created index tree.
Since the index tree was introduced, each entry operation use it to resolve the leaf block in which the operation takes place. During the life of a directory, new entries are added or removed. Whenever a leaf block if full but an operation resolved it as a target for addition of a new entry, a block is split and an index which points to this block is added to an index block on an upper level of the index tree.
Initially a single (root) index block is created. Once this block is filled up with indices, it must be split and a new root is created. In such a process a single directory data block evolves into a multilevel index tree.
Last but not least it is worth to mention that in contrary to EXT3, LFS uses pages in the page cache when manipulating with directories instead of outdated buffers (buffered IO) which makes the code more readable and maintainable.
The following sections describe in detail all main features of our implementation. In Section 5.11.2 the on-disk structures are presented, in Section 5.11.4 we describe how the target data block is resolved and how an entry is looked up, Section 5.11.5 covers how an entry is added to a directory and how the index tree is created, Section 5.11.6 shows how entries are removed, Section 5.11.8 deals with journalling support for directory operations and finally Section 5.11.9 shows how a we handle directory read by an userspace application.
An on-disk directory is represented by so-called data blocks or leaf blocks which contain the directory entries and index blocks which (if used) keeps the structure of the directory index tree.
A directory entry (or dentry) is defined as struct lfs_dir_entry (see Figure 5.11). As you can see, the name is limited to LFS_NAME_LEN which is defined in include/linux/lfs_fs.h as 256. Since we include also the trailing '0' the actual name length is limited to 255 characters. Actually the size of the name array is for userspace use (e.g. mkfs, fsck, dump_fs) and to denote the name length limit, but the size of the structure is not fixed. The length of the name is variable and is stored in the name_len item and is also determined by the trailing '0'. The name array is rather used as a pointer for accessing the entry name. The actual size of a dentry is stored in the entry_len.
Each leaf block contains at least one directory record and it spans over the whole data block. This shows that a dentry does not contain only its data, but can include free space as well. Moreover, for alignment reasons we always round the size to 4 byte boundary so up to 3 bytes might be wasted. Since the modern architectures have very slow access to any unaligned data, this is worth the cost.
When a new directory is created a single data block of this empty directory includes two dentries, for '.' and '..'. The latter is extended to cover the entire free space. As new entries are created and others are deleted, dentries are chopped into pieces of requested size or merged to avoid partitioning of the data block. This is covered in more detail by following sections.
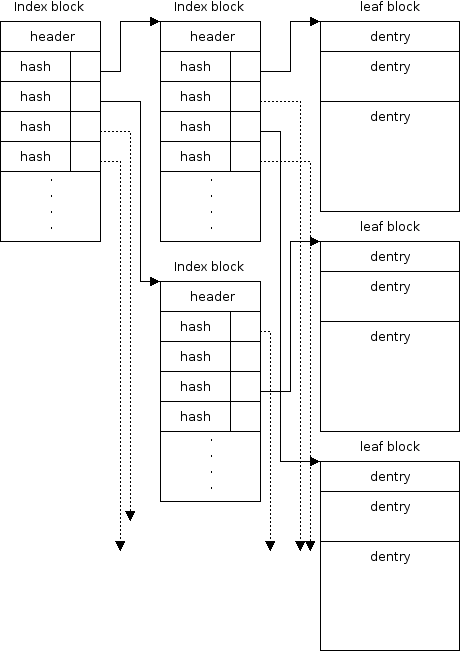
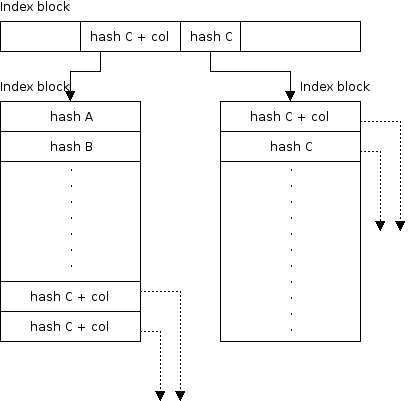
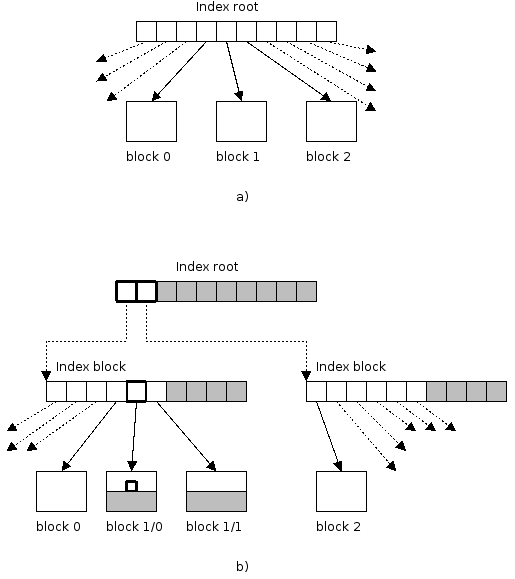
As stated before, once there are too many dentries to fit in a single directory block, an index-tree structure is created. Each index block contains a number of indices (Figure 5.12) that point either to another index-block (Figure 5.13) or directly to a leaf (data) block. Details of the index-tree is presented in the following Section 5.11.3.
As described in [7], HTREE leaves are all on the same level. Therefore the cost of resolving a block where an entry should be located, is the same for all dentries in a directory. Depth of the tree is kept in the directory's inode and helps to stop traversal from a root to the leaves. See Figure 5.14 for an index-tree example.
|
To be able to lookup dentries we assign a hash to each dentry. The hash is based on the entry's name. We opted for a 64-bit hash in order to minimize the amount of hash collisions and the length of hash collision chains. The hash function itself is adopted from the EXT3 filesystem.
Each index block contains a number of indices which map hash codes to a blocks which are either leaf blocks (a single block subtree) or a root index-block of a index-subtree. Only dentries with hash-code greater or equal to the one in the index ought to be found in that subtree. We keep the indices within an index block sorted in the ascending order of hash-codes. This allows us to use a binary search algorithm to lookup the right index. Because the hash in the index is lower bound for the hash-code within the subtree it points to, and since the same condition holds for the successive index, the next hash can be used as an upper bound for the range of indices which can be found in an index-subtree. As a result, if the dentry is not found in this subtree, the dentry does not exist in this directory at all. There is a single exception to this rule.
Because of the hash-collisions, we cannot be sure that all indices which belong to the same hash-collision chain, fits in the same block. We use a single bit in the index hash field to denote that if a dentry is not found in this subtree, the lookup should continue in the next one (see Figure 5.15). In a case of a very long collision chain, it can span several index-subtrees. Perhaps because of the 64bit (63bit since one bit is used for marking the collisions) hash size and the good design of the hash function, we never encountered a collision-chain long enough to span more than one block, though.
|
The tree depth is limited to 3 (2 index levels). This gives leaf blocks, for default settings it is equal to . This gives approx. 254MiB of leaf blocks. If we assume that each leaf block is 75% full and holds about 200 entries (see [7]), it results in approx. 13 million of entries per directory. The theoretical upper bound for maximal size entries is 993814 of entries. It is unlikely that all leaf blocks are full as well as it is unlikely that all entries have the maximal name length.
There is no practical objection to adding a third index level which would result in more then 3 billion of entries if anyone ever needs such a huge directories.
Compared to EXT3, we support less entries per directory because of the 64 bit hash and offsets. On the other hand this results in very short hash chains which do not occur very often at all.
Resolving a hash-code to a block is the most frequently executed operation in the whole directory code. The core of this operations is __resolve_leaf_blk_num() function. In case of a single block directory, its code is trivial. The only one block is returned. The more interesting job is done in resolve_leaf_blk_num_idx() which searches the index tree.
resolve_leaf_blk_num_idx() is recursive. We are sure that the depth of the recursion is not larger than the depth of the index-tree. As mentioned before, the depth of index-tree is limited to 3 (or some other small number in the future), so the depth of the recursion is as well. The small depth of the recursion is why we use this rather than any stack-based non-recursive workaround.
This function can perform several slightly different tasks. The basic use is to lookup the leaf block with the first occurrence of a given hash. If a hash collision was detected, this function can be called in a loop with the last returned block passed in, so the function looks up the next block in a hash collision chain until the end of the collision is found. If requested, it can return the index block that points to the leaf block that was returned. This is useful, e.g. if we want to remove an empty leaf block and mark it in the index tree. This feature is not used though. Of course, this function can also return an IO error.
Resolving a hash to a leaf block is only part of the lfs_lookup() inode operation since resolve always returns a blocks where the requested hash might be, unless an IO error occurred. To be sure that an dentry is present in the returned block, a traditional linear search must inspect that leaf block.
The search must be linear because dentries are not sorted within a leaf block. We decidedi so because of the high cost of keeping dentries ordered (See Section 5.11.5 on how dentries are added). Instead, we store the hash code of each dentry together with the dentry name in each dentry record. Therefore we do not have to do a string comparison if hash does not match. On the other hand, if the hash in the dentry is equal to the hash-code of the looked up record, we must compare the name string to be sure that we found the correct dentry and not just a dentry with the same hash in a collision chain. For details see the lfs_name_to_inode() which walks the leaf block and lfs_name_match() which does the string comparison.
Adding new directory entries is the most complex directory operation. First,
the target leaf block must be found. If there is no space for a new dentry,
the block must split and a new index is inserted in the upper index block. This
may lead to a cascade of index block splits which can exceed the index-tree
limits (as presented in Section 5.11.3 on
page ![[*]](crossref.png) ). This is reported to the user
application as -ENOMEM We will now describe in detail all actions
necessary to add a new directory entry.
). This is reported to the user
application as -ENOMEM We will now describe in detail all actions
necessary to add a new directory entry.
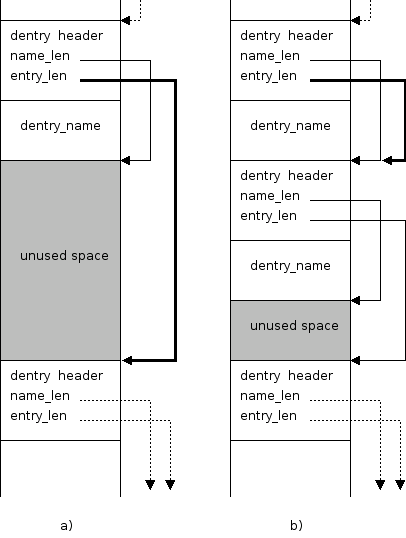
Once a target block is resolved (as showed in Section 5.11.4) the insert_dentry() attempts to insert the dentry. We use the word attempts because there is no way to predict whether the insert operation will be successful or not.
The function starts at the beginning of the data block and linearly walks the list of all dentries present in the block until it finds a suitable location for the new entry or until the end of the block is reached.
As stated in Section 5.11.2 on
page , the whole block is covered by
struct lfs_dir_entry structures. Each dentry structure points to its
successor with its entry_len field, creating a linked list within the
data block. All unused space is included in dentries. Therefore
suitable place for a new dentry record can be found in
|
Because a directory leaf block becomes fragmented as new entries are added and removed, it might happen that there is enough unused space in the block, but no chunk is large enough. Since we want to prevent unnecessary block splitting, we defragment such blocks.
When walking the linear list of all dentry records, insert_dentry() counts the number of unused bytes. Because no suitable space was found, the end of the list is reached and all space is accounted. If the space i large enough for the new dentry, block_defragment() is called. Once the block has been defragmented, we try to add the new entry again. This time success is guaranteed.
block_defragment() just pushes unused space to successive records. It is finally gathered in a single empty dentry record at the end of the block. For details see Figure 5.17 and the code in src/dir.c
|
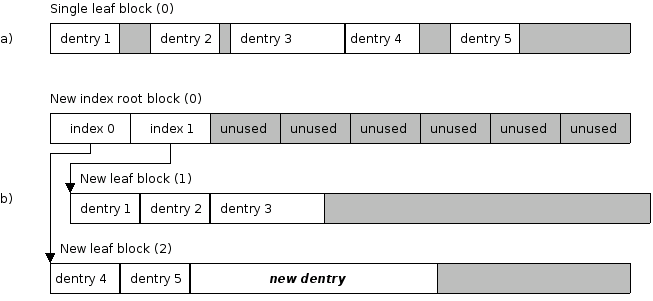
As stated before, each newly created directory has a single leaf block. When adding a new dentry in this block (as described before), sooner or later it will happen that insert_dentry() returns -ENOMEM because there would not be enough space even after defragmentation (defragmentation is not executed because it would be useless).
In this case the single leaf block is split in two and a new index root block is allocated. Approximately half of all dentries in the original block are copied to each of the new leaf blocks and indices of both blocks are inserted in the index root (See Figure 5.18). Although copying data from one block to another is expensive, we benefit at least that the block is defragmented while data are copied. copy_half() copies dentries from the original block to the new one and deactivates the original dentries by setting their inodes to LFS_INODE_UNUSED_LE32. Unfortunately this cannot be done simultaneously because of page locking. In case of a different block and page size (note that block size is always less than or equal PAGE_CACHE_SIZE), we might access blocks which resides in the same page. This is exactly the case when splitting a single block directory as at least one of the new blocks is allocated in the same page as the block that is being split. Therefore data are copied first and the original block must be walked once again to deactivate the copied dentries.
|
If an index tree already exists and a new dentry is being added there are basically three scenarios :
When splitting a leaf block, there is a special case of a single block directory (first split), which is a has no index block. It is just a single leaf block and must be handled accordingly. The difference is that data from the original block must be moved to another location within the file because index root must be always in the first block of the directory, so we can easily find it. In any other case the block that is being split is not moved, approximately half of its entries are copied to another block and the original block is defragmented. The core of this operation is implemented in __split_leaf_block() function.
The strategy for splitting a leaf block is fairly simple. Function map_create() reads the whole block and creates a so-called map of that block. The map contains an address of each dentry in the block together with its hash. Here we benefit from the fact that the hash is stored in each dentry so that we do not have to calculate it. After the map is created, it is sorted in map_sort() in ascending order of hash codes. This is necessary because of the fact that hash of records which are about to be copied to the new block must be all greater or equal than some value which is stored in a new index. The upper half of the hash codes is copied to its new location using copy_half().
This method proved to work fine. It assures that there will be space enough for a new entry except in certain corner cases, where it is not technically possible, e.g., in a case of smallest block size of 512 bytes if there is already a dentry with maximal name length of 256 characters. Adding a new maximal size dentry is not possible. In such a case -ENOSPC is returned. We do not treat this as a significant problem since it is the administrator's task to create a filesystem that suites his needs.
Of course, there are some obvious improvements to this method that are considered future work. For instance :
After a leaf block is split, the index which points to this block must be placed in an index block. This operation, performed by insert_index_into_block(), called from insert_new_index(), is fairly simple if there is a free slot in the index block. To be able do check it quickly, each index block has a header (See Figure 5.13) that stores how many slots are in this block and how many are actually used.
As stated before, all entries in an index block are ordered, so we use a binary search to find the position where the new index should be inserted. Function insert_index_shift() shifts the rest of the indices and places the index at the freed position. The whole process is illustrated on Figure 5.19
|
The task of insert_new_index() is to handle a cascaded split. As stated before, it might happen that there is no free slot left so that the index block must split. Call to split_idx_block() returns the index of the newly created index block and a recursive call to insert_new_index() inserts it to the upper index block. Perhaps this index block must also be split and so on. The recursion continues until the index is successfully stored or until the index root is split and a new index-root is created. There is always space enough and the recursion stops. Figure 5.20 shows such a situation.
|
In Section 5.11.4 we mentioned that we use recursion for
traversing the index-tree when resolving hash-code to a leaf block. Maximal
depth of the index tree limits the depth of this recursion (See limits in
Section 5.11.3 on page ). The
same condition holds for the bottom-up recursion of the cascaded split.
Because we need new blocks in the cascaded split, we must be sure that we do not leave the directory structure in an inconsistent state if we run out of memory. Therefore insert_new_index_probe() tests to which extent the directory will be split and tells how many blocks to preallocate. Last but not least, it detects whether the maximal depth of the directory is going to be exceeded and if so returns error code -ENOSPC. This signals that there is currently no space in this directory for the entry. It does not mean that another (different) entry cannot be inserted and by doing so, the index-root must not be split. Unfortunately, this information is opaque to the userspace application. References to the preallocated blocks are passed to the splitting-part of the directory-code so that no dangerous allocation is necessary. If preallocating of necessary number of blocks fails, so does inserting of a new entry.
Comparing to adding a new directory entry, removing an old one is significantly simpler. We opted for solution which is not shrinking the size of the directory since most entries are removed not from last block in the directory file (and so we could truncate the directory once the last block is empty) but rather from random blocks within the file.
To remove or delete an entry, it must be looked up as described in Section 5.11.4. Subsequently, the entry is marked as unused by setting its inode item to LFS_INODE_UNUSED. Doing only this would result in fragmentation of the directory leaf block. If there are unused neighbors, we merge them with the newly released entry to create a larger unused chunk within a block. This chunk can be more easily reused by following add/create directory operations. The core of the remove operation is implemented in lfs_remove_entry(). This function is reused in all directory operations that remove entries from a directory, which include
The described method of removing directory entries has drawbacks too. The most obvious is that we do not shrink the directory's size if some leaf blocks are emptied. This can result in a huge directory (in terms of used bytes on disk) that contains only several entries, which might fit in a single block directory. As well known and extensively used filesystems do not deal with this problem either, we consider this as a minor issue. It is unlikely that applications that create a large number of entries will not remove the whole directory once its entries are not used anymore.
Another problem is that the index-tree structure is more or less static. It means that once a tree is created and indices are distributed among index-blocks the only operation that can possibly change such a distribution is adding new entries (and splitting tree nodes). Removing entries does not affect the tree structure at all. Here we highly benefit from the well designed hash function5.12. It distributes entries very well so even a different work-scheme on previously emptied directory keeps the usage of both index and leaf blocks balanced.
We considered an option of releasing leaf blocks. The problem is that the Linux VFS layer makes releasing blocks within a file difficult. Another space optimization would be merging and releasing index blocks. This would affect the overall performance of directory operations significantly. In our opinion this might be a task for a Garbage collector or similar process which can compact directories once the system is idle.
Both extensions remain future work.
We support fast and slow symbolic links in the EXT2 fashion. Fast symbolic links store the destination path in the the struct lfs_inode area which is reserved for block addresses. Since we use 64 bit addresses, there is space for up to 192 characters. If the path is longer, it is stored as a slow symbolic link in a single data block.
While our filesystem works as a log, we need journaling for directory operations. The reason is that we cannot be sure, which data are going to be written to the disk and when. Moreover the disk itself can reorder writes of the data. If the system crashes, roll-forward needs to know which operations were performed since the last sync to be able to remove entries if inodes are missing.
Before a directory operation starts changing data blocks, it tells the journalling subsystem (See Section 5.12) which operation will change the directory. The following operations, defined in include/linux/lfs_dir.h are journaled :
Journal is divided in so-called journal lines (or jlines) of variable length. The length depends on the operation that is journaled. In general, each line has a header which describes the operation and its variable parameters. Figure 5.21 present the header of the on-disk journal line. The header is followed by one or two strings depending on how many names are used for each operation.
We can divide all operations into three groups :
Operation rename needs special care if the destination already exists. The expected behavior is that unless the target is a non-empty directory, the target is removed and substituted by the moved entry. Such a situation needs to journal both rmdir/unlink and rename.
Core of the directory journalling is lfs_journal_dir_writeout() which creates the journal line and passes it to the journalling subsystem. Extra care must be taken if a journal line spans across a page border. There is a state machine inside the lfs_journal_dir_writeout() which fills the actual page and asks for another page.
The readdir operation is used for sequential reading of all directory entries. It is not directly exported to userspace even though there is a readdir() function in standard libraries. Its purpose is to return a single entry per call. Asking the kernel to return a single entry each time is not efficient since crossing kernel-userspace boundary is expensive. Therefore the Linux kernel exports the getdents() syscall which gets a buffer from userspace an fills it with as many entries as possible and let the glibc implementation of getdents() deal with system specific differences of how to get data to userspace buffers. Glibc's readdir() returns a single entry from that buffer. We will now discuss how the directory entries are read by LFS and how they are returned to userspace.
Like the rest of the Linux VFS, readdir() expects behavior similar to EXT2, therefore our implementation is not straight forward but deals with similar problems as EXT3 with indexed directories. There are certain differences.
The main problem is that file position in the traditional meaning does not make sense. If we were sequentially walking a directory that is being changed by another process, we might see some entries more then once. The reason is that some entries could have been copied to another block because of an index-tree split. Even if we were able to skip index blocks (which do not contain any entries) we cannot determine if some entry was already returned or not.
We compared behaviour of LFS and EXT3 on a directory with 500.000 entries. We used an old glibc's implementation of readdir() which performes more then 4.000 seeks. LFS returns two duplicities whereas EXT3 only one.
In our approach, we substitute the real file position by the hash value of the actual directory entry. This value expresses where such an entry can be found. If the directory is walked in the hash order, it is simple to tell whether the given entry was already sent to a user application or not by comparing its hash value with the actual one.
Another issue is to determine where to continue reading when readdir() is called. There are two situations :
As stated before, each call to readdir() returns just as many entries as many fit in the given buffer. To read the whole directory, a user application issues several calls. In each invocation we need to know where to continue.
Just as it is possible to seek in a regular file, it is also possible to seek 5.13 in a directory. After seeking, readdir should continue from the new position.
As described before, we use a hash instead of a real file position. This allows us to determine position in the sequence of entries sorted by hash codes. The drawback is that this is not unique since there are entries with the same hash code in case of a hash collision. So it is not possible to tell exactly which entry is referenced.
To reduce the probability of hash collisions we opted for a 64 bit hash. It is problematic to return such a large file position in readdir(). Even though all related kernel functions use loff_t which is a 64 bit integer type, glibc expects 32 bits only. Therefore we return only the most significant bits. As a result seeking is not precise. But as there might be many concurrent writer 5.14 the application cannot count on that the directory is in the same state all the time, unless some other means of synchronization or mutual exclusion are used.
As described earlier, an application calls readdir() as long as there are some data to be returned. Each time, as many as possible entries are returned. Only EOF is signaled by returning no entriy. We need to remember where to continue after being called again. For earlier mentioned reasons, file position (e.g., as used in EXT2) is not enough since this information is not accurate enough. Therefore we attach a private data structure to the struct file structure (See Figure 5.22), where we keep all important data between successive readdir() invocations. It includes last file position (to be able to detect seeking), current hash to be processed, entries of the block which is being processed and a list of all leaf blocks. The last two items are described in more detail later on.
Because of the data stored in the private info structure, we need to detect if the application changed the actual file position (seek, etc.). To do so, we keep the last file position just before returning from the previous readdir() call. If seek is detected, the private data structure must be reset and refilled accordingly.
Similar measures are taken if a directory is changed while being read. We wish to return the most recent state of the directory, but this is not always possible. If a new entry with a lower hash than the current is added, this entry is not to be returned without seeking or rewinding that directory. Returning such an entry would violate the hash order. Moreover adding new entries to a directory may split some blocks and some of the entries wouldn't be returned at all. For this reason, we need to reload the private info if the directory changes. We keep an internal version of the directory. If it has changed since the directory was opened or since the private info was reloaded, it is time to reload it again.
As stated before, we decided to return all entries in hash order rather than in file position order. The directory is partially ordered because of the index-tree structure. As described in Section 5.11.4 records in index blocks are ordered, contrary to leaf blocks which lack any sense of order. As a result we read the leaf blocks in the hash order and sort the content of a block when the block is being processed.
When readdir() is called for the first time, no private info is attached to the directory yet, we create a list of all directory leaf blocks. There are several reason to do this :
The list of block indices is created in fill_idx_list() which walks the index-tree in depth-first-search and adds an index of a leaf block to the list. The list itself consists of a linked list of pages. Each page is allocated in alloc_idx_list_item() Each page contains a header (See Figure 5.23) and an array of indices. When adding a index of a block to the list, we call get_dir_block() to get the block to memory.
This list is attached to the directory's private structure. As readdir() is called, the first item in the list is removed and processed. After a block is finished, put_dir_block() is called to release a reference to the block. Once all indices are removed from a page, the page is released in free_idx_list() too. free_idx_list() releases all items on the list. In most case just a single-item list is passed to this function, unless a reset of the whole private structure occurs
We need to sort all entries of a block in hash order. We adopted an EXT3-like approach. Its core is a red-black tree (rb-tree) where each node represents a single hash value and its collision chain. We use the generic rb-tree implementation from the Linux kernel. The rb-tree is sorted when new nodes are inserted.
Initially the rb-tree attached to the private info is empty. Everytime the rb-tree is empty, lfs_fill_rb_tree() is called. It picks up a block from the index list (as described in previous subsection) and calls block_to_rb_tree() to fill the rb-tree with data from the leaf block. If there is a collision chain that overflows to another leaf block, the whole chain is read and inserted into the rb-tree. If in the meantime some entries were removed from the directory, it might happen that there is an empty block in the list. That block is skipped.
The rb-tree is reference through the root item of the private data structure. curr_node points to the node which is currently processed and curr_chain is the first item in the hash collision chain which will be processed next. For details see Figure 5.22 and the src/dir.c source file.
The core of readdir() implementation is a loop which calls filldir(). From the point of view of readdir(), filldir() is a blackbox wrapped in lfs_filldir().
The main loop is responsible for setting the current node of the rb-tree. If the rb-tree is emptied, it is refilled again. In contrary, lfs_filldir() processes a single hash chain. It calls filldir() for each item in the chain and if an error is returned, it sets the curr_chain so next the readdir() can continue from here on. Notice, that the before mentioned error is not fatal and its only purpose is to signal that the userspace buffer is full.
Because we allocate a private data structure that we attach to the directory once the readdir() is called for the first time, we must be sure that those data are freed by lfs_release_dir() file operation once the directory is closed.
The journaling subsystem can be found in src/journal.c and its purpose is to provide the directory operations with a means to store jlines (see section 5.11.8) and enable the segment building subsystem (see section 5.3.5) to flush to disk those of them which are relevant to the currently written entity. Internally, the subsystem is little more than a queue of pages, a current page to which new entries are being added and a counter of jlines to uniquely identify them.
Directory operations start creating jlines by calling lfs_journal_grab_entry(). This function returns the pointer to the current position in the current page and how much space there is left in it. If there is no current page a new one is allocated. This function also locks a mutex so that no journal entries ever interleave and the subsystem state is protected from race conditions.
Conversely, when a directory operation is done with constructing a jline, it calls function lfs_journal_release_entry() so that the journaling subsystem can update its state, in particular the position in the current page and the number of the next jline and release the mutex. If the current page has been entirely filled by the committed jline it is queued. Finally, the subsystem checks whether the journal pages take too much space and if it is so, the segment building code is asked to plan a few of them and finish a partial segment so that the memory they occupy can be freed (see section 5.3.1). The function returns the number of the finished jline so that the directory operation can assign it to corresponding fields of relevant inode infos.
Nevertheless, the jline a directory operation wishes to produce may not fit into the remaining space in the page. The operation must handle this by splitting it into two parts so that the first one exactly fits into the rest of the current page and ask for a new pointer by calling lfs_journal_next_page() which enqueues the current page and allocates a new one so that the rest of the jline can be placed into it. This function keeps the journal mutex locked.
Whenever the segment building code processes an inode, mapping or even a single page, it must acquire and plan plan all pages containing jlines with a number that is less than or equal to the one stored in the inode info. These are obtained by calling lfs_flush_inodes_journals(). In addition, if there are too many journal pages stored in the queue, this function passes some of them on to the caller too. The caller then processes the returned part of the queue and plans it with respect to plan structures, remaining blocks in the segment and so on.
Viliam Holub 2006-12-04